

Алексей Терехов, медиаэксперт, Internews
Чтобы получить от ИИ максимум, журналисту нужно стать инженером — контекстным инженером. Хорошая новость: в основе этой роли лежит то, что журналисты и так должны уметь — точно ставить задачу, задавать правильные вопросы, давать собеседнику нужный контекст. На профессиональном языке это называют context engineering — и именно этот навык позволяет редакции из пяти человек работать с масштабом, который ещё недавно требовал штата втрое больше.
Если в вашей редакции ChatGPT или любая другая языковая модель работает быстро, но результат не радует — текст звучит «по-ИИшному», далёкому от редакционного стиля; загруженный документ обобщается, но теряется ключевая цифра; заголовки больше похожи на маркетинговые слоганы — то проблема, скорее всего, не в модели. Проблема в том, как ей поставлена задача, какой контекст она получила и получила ли вообще.
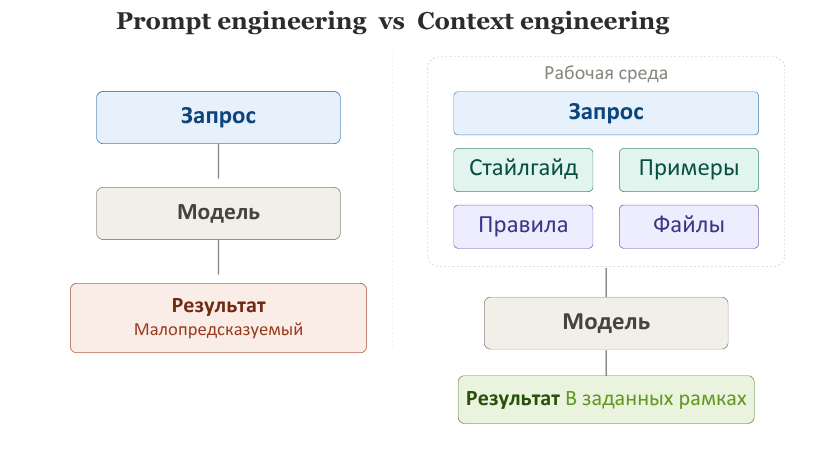
От prompt engineering к context engineering
На базовом уровне prompt engineering — это искусство хорошего запроса. Вы задаёте модели роль, объясняете задачу, уточняете формат, ограничения, тон, длину, критерии результата. И сразу получаете ответ заметно лучше, чем при запросе “напиши мне хороший текст”.
Но максимальную пользу редакция получает тогда, когда работает с ИИ не через случайные одноразовые запросы, а через постоянные рабочие рамки. То есть когда модель получает не только сам запрос, но и всё, что делает этот запрос осмысленным: контекст материала, стиль издания, примеры хороших текстов, запрет на домысливание фактов, требования к цитатам, список допустимых источников, формат выдачи.
Вот это и есть context engineering.
Термин начал быстро входить в профессиональный обиход в середине 2025 года, когда его практически одновременно озвучили Андрей Карпатый, научный сотрудник и один из первых создателей OpenAI, и Тоби Лютке, генеральный директор Shopify Shopify.
Разница между подходами простая. Prompt engineering — это как правильно задать вопрос эксперту. Context engineering — это как заранее собрать для него папку с документами, справками, инструкцией и примерами. В первом случае вы надеетесь на удачную формулировку. Во втором — вы проектируете среду, в которой модель с большей вероятностью даст нужный результат.
Любая редакция уже может собрать себе целую команду виртуальных ассистентов: один помогает разбирать интервью, другой — обобщать документы, третий — адаптировать тексты для платформ. Но, как и в любой команде, всё решает постановка задачи. Без нормального брифа результат будет посредственным.
Когда вы создаёте кастомный чат, загружаете стайлгайд, примеры, рабочие документы и задаёте правила — вы уже занимаетесь context engineering. А когда система ещё и подтягивает под конкретный запрос прошлые публикации, нужные файлы, источники и ограничения — это становится по-настоящему мощным инструментом.

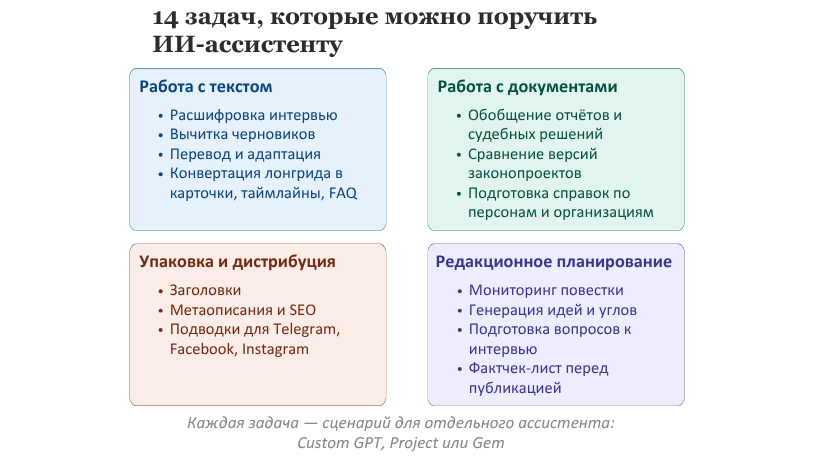
Где ИИ реально экономит время
Наибольшую отдачу ИИ приносит не в написании финальных материалов, а там, где в редакции больше всего рутины.
Первичная обработка интервью. В связке с сервисом распознавания речи модель может быстро превратить транскрипт в структурированный черновик: выделить ключевые тезисы, сгруппировать ответы по темам, предложить логику будущего материала.
Работа с длинными документами. Когда журналисту нужно быстро разобраться в докладе, законопроекте или судебном решении, модель может выделить основные выводы, ключевые цифры, ограничения документа и вопросы, на которые он не отвечает. Это не замена чтению, а ускорение навигации по сложному тексту.
SEO-адаптация и упаковка для платформ. Заголовки, лиды, метаописания, подводки для Facebook или Telegram — всё это модель делает достаточно хорошо, если ей заранее задать рамки конкретного издания: тон, длину, допустимую лексику, запрет на кликбейт.
Черновые справки и бэкграунды. Модель может быстро собрать исходную структуру по теме, персоне или организации — не как готовую публикацию, а как стартовую точку для журналистской проверки. Здесь критически важно одно правило: ИИ должен маркировать неуверенные утверждения и не выдавать предположения за установленный факт.
Поиск тем и генерация идей. Один из самых недооценённых сценариев. Модели с доступом к интернету могут работать как редакционный радар: помогать замечать новые темы, всплески обсуждений, потенциальные манипуляции и слабые места в публичной повестке.
Во всех этих случаях ИИ полезен не потому, что «умеет писать тексты». Он полезен потому, что снимает часть производственной нагрузки и освобождает время для собственно журналистской работы.
Что ИИ не заменяет
Но здесь и проходит важная граница. ИИ не заменяет журналистское суждение. Не заменяет редакторское чутьё. Не заменяет этическую ответственность. Модель не понимает контекст так, как его понимает человек, который месяц следит за темой. Она не проверяет факты в человеческом смысле. Она не отвечает за ошибку. За ошибку отвечает редакция.
Поэтому разговор о context engineering — это не только разговор об эффективности. Это разговор о дисциплине. О том, как встроить ИИ в работу так, чтобы он усиливал журналиста, а не создавал опасную иллюзию, что черновик уже равен готовому материалу.
Каждый автоматически собранный бэкграунд требует проверки. Каждый обобщённый документ нужно сверять с оригиналом. Каждый заголовок, предложенный моделью, должен пройти редакторскую оценку. Иначе вместо ускорения вы получите дополнительный слой ошибок.
Как это устроено в ChatGPT, Claude и Gemini
У разных моделей разные сильные стороны. ChatGPT удобен там, где редакции нужна библиотека специализированных ассистентов. Custom GPTs позволяют задать роль, инструкции, загрузить файлы и подключить инструменты. Хороший вариант для редакций, которые хотят быстро собрать набор рабочих ассистентов без технической команды.
Claude особенно силён в работе с длинными документами и аналитическими задачами. Его формат Projects подходит там, где нужно постоянно держать под рукой стайлгайд, архив публикаций или массив аналитических материалов.
Gemini наиболее интересен редакциям, у которых рабочий процесс уже завязан на Google Docs, Drive и Gmail. Его преимущество — интеграция с рабочей средой и сильный поиск.
На практике многим командам разумно использовать не одну модель, а две или три — под разные сценарии. Одну для ежедневной рутины, другую для аналитики, третью для интеграции с рабочей средой.
С чего начинать внедрение
Выбрать один конкретный сценарий, где редакция теряет больше всего времени. Например, расшифровка интервью. Или обобщение документов. Или подготовка SEO-упаковки. Или мониторинг повестки.
Первый шаг — описать для этого сценария рабочую рамку: роль модели, тип результата, ограничения, доверенные источники, критерии качества и правило обязательного человеческого одобрения.
Допустим, вы начинаете с расшифровки интервью. Запрос к модели может выглядеть так:
«Ты — редакционный ассистент. Вот транскрипт интервью. Структурируй его по темам, выдели ключевые цитаты дословно. Не переформулируй прямые цитаты, не додумывай то, чего нет в записи. Результат — черновик на 800–1000 слов с разбивкой по тематическим блокам.»
Это prompt engineering — сформулированный запрос. Протестируйте его в обычном чате. Если результат устраивает — переходите к следующему этапу.
Context engineering. В ChatGPT вы создаёте Custom GPT: вписываете этот запрос как постоянную инструкцию в поле Instructions, добавив строку «при ответе опирайся на файлы из раздела Knowledge», а в сам раздел Knowledge загружаете стайлгайд издания и пару примеров удачных расшифровок.
В Claude — открываете Project, добавляете те же файлы в Project Knowledge и пишете в Custom Instructions памятку «чего мы никогда не делаем».
В Gemini — создаёте Gem, подключаете Google Doc со стайлгайдом прямо из Drive.
Всё. Теперь модель каждый раз работает в нужных рамках без дополнительных объяснений. Вы не повторяете инструкции — они уже внутри. Не один запрос, а настроенная рабочая среда. Это и есть context engineering на практике.
Второй шаг — повторить это для следующего сценария. Расшифровка заработала — настройте по такому же принципу рабочую среду для обобщения документов. Потом для SEO-упаковки. Каждый новый проект — это ещё один ассистент в вашей редакции.
Третий шаг — назначить одного-двух человек, которые будут координаторами процесса: собирать удачные находки, делиться ими с коллегами, помогать тем, кто пока не разобрался.
Один сценарий, один ответственный, пара недель на внедрение. Потом — следующий. Именно так ИИ становится частью производственного процесса.
Базовый ИИ-комплект редакции
Со временем у редакции складывается набор из пяти элементов.
Библиотека настроенных ассистентов — Custom GPTs, Projects или Gems под ключевые роли: расшифровщик интервью, ассистент по документам, SEO-упаковщик, бэкграунд-ассистент, редактор-вычитчик, переводчик или адаптатор.
Редакционный стайлгайд для ИИ — короткий документ, который объясняет модели, каким должен быть тон, чего делать нельзя и по каким признакам ответ считается удачным. Загружается в Knowledge или Project Knowledge каждого ассистента.
Протокол верификации — простые правила: что обязательно проверяется вручную, что можно использовать как заготовку и кто отвечает за финальную версию.
Внутренняя песочница — чат, канал или документ, где команда делится удачными находками, ошибками и новыми рабочими рамками, чтобы знания не оставались в личных чатах.
ИИ-координатор — один или два человека, которые помогают коллегам настраивать ассистентов и встраивать их в ежедневную работу.
Получается новая редакционная инфраструктура.
В ближайшие годы конкурентным преимуществом редакции станет не доступ к ИИ — он будет у всех. Преимуществом станет умение давать модели правильную роль, правильный контекст и правильные границы. То есть то, о чём мы говорили выше — context engineering.
Анализ был подготовлен в рамках проекта «Устойчивая пресса, информированные избиратели: защита выборов в Молдове от дезинформации», при финансовой поддержке Посольства Королевства Нидерландов в Молдове. Мнения, выраженные в материале, принадлежат авторам и не обязательно отражают позицию донора.